728x90
💡 N+1 문제란?
연관관계가 설정된 엔티티(1)를 조회할 때, 조회된 데이터의 수(N)만큼 연관관계의 조회 쿼리가 추가로 발생하여 데이터를 읽어오는 문제를 말한다.
📌 Example : N + 1 재현하기
@Setter
@Getter
@Entity
@NoArgsConstructor
public class Rich {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "rich", cascade = CascadeType.ALL, fetch = FetchType.EAGER) // 즉시호출
private List<Car> cars = new ArrayList<>();
public Rich(String name) {
this.name = name;
}
}@Setter
@Getter
@Entity
@NoArgsConstructor
public class Car {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String model;
@ManyToOne
@JoinColumn(name = "car_id")
private Rich rich;
public Car(String model) {
this.model = model;
}
}- 한 명의 부자가 여러 대의 자동차를 가지고 있다.(다대일 양방향 매핑)
@SpringBootTest
public class NPlusOneTest {
@Autowired
CarRepository carRepository;
@Autowired
RichRepository richRepository;
@Autowired
EntityManager entityManager;
@Test
@Transactional
@Commit
void test() {
List<Car> cars = new ArrayList<>(); // cars 리스트 객체 생성
for (int i = 1; i <= 10; i++) {
cars.add(new Car(("Model" + i))); // cars 리스트에 car 추가
}
carRepository.saveAll(cars); cars 리스트를 DB에 저장
List<Rich> riches = new ArrayList<>(); // rich 리스트 객체 생성
for (int i =1; i <= 10; i++) {
Rich rich = new Rich("rich" + 1);
rich.setCars(cars); // rich에 위에서 생성한 cars 추가
riches.add(rich); // riches 리스트에 rich 추가
}
richRepository.saveAll(riches); // riches 리스트를 DB에 저장
entityManager.clear(); // 확실한 결과 도출을 위해 EntityManager 초기화
System.out.println("----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------");
List<Rich> allRiches = richRepository.findAll(); // 모든 rich를 DB에서 불러옴
Assertions.assertFalse(allRiches.isEmpty());
}
}- 자동차 10대 생성
- 부자 10명 생성
- 부자 1명당 자동차 10대를 가지고 있음
- 부자 리스트를 DB에서 불러올 때 N+1 문제가 생기는지 확인(부자의 자동차 리스트를 조회하는 쿼리도 함께 호출되는지)

- Hibernate SQL log를 활성화하여 호출된 쿼리를 확인 가능하다.
select rich0_.id as id1_1_, rich0_.name as name2_1_ from rich rich0- 부자를 호출하는 쿼리가 처음 나오고,
select cars0_.car_id as car_id3_0_0_, cars0_.id as id1_0_0_, cars0_.id as id1_0_1_, cars0_.model as model2_0_1_, cars0_.car_id as car_id3_0_1_ from car cars0_ where cars0_.car_id=? ... - 부자의 차를 조회한 row의 만큼 차를 조회하는 쿼리가 호출된다.(N+1 문제 발생)
- 부자를 호출하는 쿼리가 처음 나오고,
❓ 혹시 FetchType.EAGER (즉시호출)을 했기 때문일까? LAZY(지연로딩)으로 바꿔보자.
public class Rich {
...
@OneToMany(mappedBy = "rich", cascade = CascadeType.ALL) // default : LAZY
private List<Car> cars = new ArrayList<>();
...
}
- rich를 조회하는 쿼리 하나만 호출되었다.
🤔 의심
그러나 FetchType을 LAZY로 설정하면 즉시 조회되지 않는 것일 뿐이다.(연관관계 데이터가 프록시 객체로 바인딩되기 때문) 아마도 지연로딩이 되는 시점(실제 객체의 호출 시점)에 부자의 차를 조회하는 쿼리가 호출될 것이다.
@SpringBootTest
public class NPlusOneTest {
...
List<Rich> allRiches = richRepository.findAll();
List<String> carModelName = allRiches // 실제 객체 호출
.stream()
.flatMap(rich -> rich.getCars()
.stream()
.map(car -> car.getModel()))
.collect(Collectors.toList());
Assertions.assertFalse(allRiches.isEmpty());
}
}- 부자의 자동차 리스트에서 각 자동차의 모델명을 호출했다.
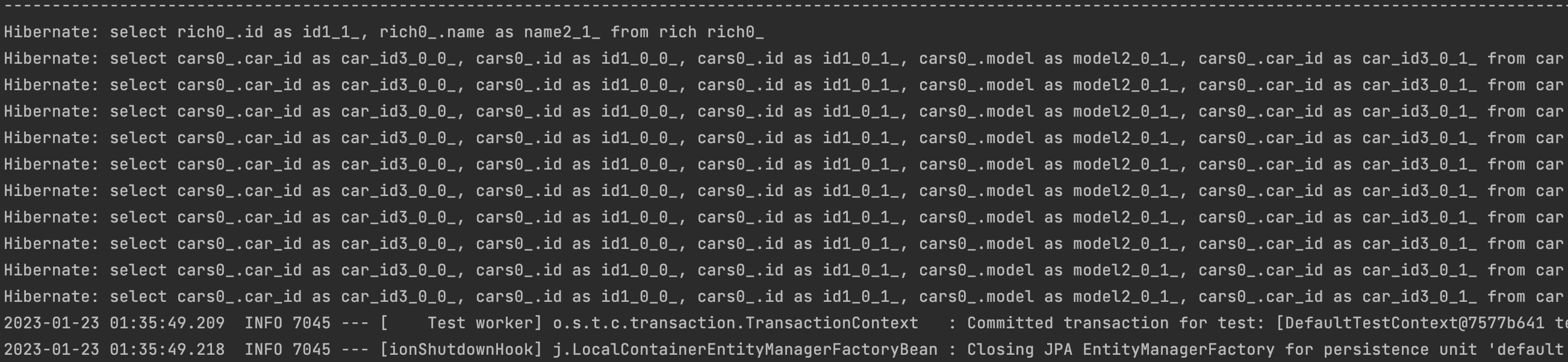
- 로그를 확인해 보면 LAZY(지연로딩) 역시 N+1 문제가 발생한다는 것을 알 수 있다.
- FetchType의 변경은 N+1 문제의 발생 시점을 늦출 뿐 해결책이 될 수 없다.
📌 N+1의 발생 원인
JPARepository에서 정의한 인터페이스 메서드를 실행하면 JPA가 메서드를 분석하고 JPQL을 생성하여 실행한다. JPQL은 특정 SQL에 종속되지 않아 엔티티 객체와 필드의 이름만을 가지고 쿼리를 생성한다. 따라서 findAll() 메서드가 수행되면 해당 엔티티만을 기준으로 한 조회 쿼리가 생성된다. 결론적으로 select * from rich 쿼리만 실행이 되고, FetchType으로 지정한 실제 객체를 불러오는 시점에 별도의 조회 메서드를 호출하게 되는 것이다.
💡 해결방안
Fetch Join

- INNER JOIN을 이용하기 때문에 연관관계가 있어도 하나의 쿼리문으로 표현이 가능하다.
- 최적화된 쿼리를 직접 작성함으로써 해결할 수 있다.
@Query("select o from Rich o join fetch o.cars")
- 단점
- fetch join을 사용하게 되면 데이터 호출 시점에 연관관계의 데이터를 가져오므로 FetchType 설정이 무의미하다.(LAZY)
- 하나의 쿼리문으로 가져오기 때문에 페이징 단위로 데이터를 가져오는 것이 불가능하여 페이징 쿼리를 사용할 수 없다.
EntityGraph
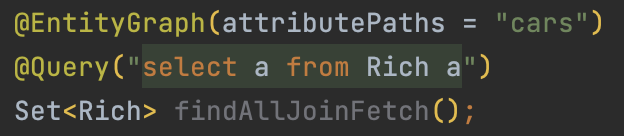
@EntityGraph(attributePaths = "cars")와 같은 애너테이션을 추가함으로써 LAZY가 아닌 EAGER 조회로 가져오도록 설정할 수 있다.- fetch join과는 다르게 join 문이 outer join으로 실행된다.
Fetch Join과 EntityGraph의 공통점과 사용 시 주의할 점
- JPQL을 사용하여 JOIN문을 호출한다는 공통점이 있다.
- 둘 다 카테시안 곱(Cartesian Product)이 발생하여 Rich 수만큼 car의 중복 데이터가 생기는 상황이 발생할 수 있다.
- 중복을 제거하기 위해서 List 대신에 Set 컬렉션을 사용하여 해결한다.
- JPQL을 사용하므로 distinct를 사용하여 중복 데이터를 조회하지 않을 수 있다.
BatchSize

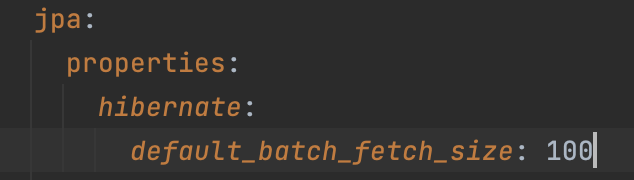
- BatchSize는 JPA에서 제공하는 기능이다.
- 상위 엔티티 안에 있는 하위 엔티티가 IN 절에 들어간다.
- 한 번 쿼리를 날릴 때, 지정한 Size 만큼 하위 엔티티를 IN 절에 포함하므로 쿼리수가 눈에 띄게 줄어든다.
- Size는 100~ 1000이 적당하다고 한다.(정보 불확실)
- N+1의 문제를 해결할 수 있는 가장 대중적인 방법인듯하다.

- 사진과 같이 설정한 사이즈만큼 or 사이즈보다 데이터의 크기가 작다면 데이터의 크기만큼 한 번에 조회할 수 있다.
- 처음 조회를 제외하고 추가적으로 발생하는 쿼리가 N번이 아닌 한 번씩만 발생하게 된다.
- 사용하는 방법은 BatchSize를 적용하고 싶은 클래스, 메서드, 필드 등에 애너테이션을 붙이거나, yml or properties 파일에 설정하면 된다.
- yml or properties의 경우 애플리케이션 전역에 적용할 수 있다.
- 페이지네이션이 적용되어 있어도 사용할 수 있다.
- 데이터의 사이즈가 설정한 BatchSize보다 월등히 많다면 에러가 발생할 수 있다.
📌 정리
실전에서 위 방법만으로는 한계가 존재하는 것 같다. 다른 방법이 몇 개 있는 것 같지만 일단은 여기까지 정리하겠다.(SQL에 대한 깊은 이해가 필요해 보인다.)보다 자세한 내용은 참고했던 블로그를 들어가서 확인해 보길 바란다.
참고 : https://incheol-jung.gitbook.io/docs/q-and-a/spring/n+1
728x90
'[JAVA] > JPA' 카테고리의 다른 글
| JPA - 프록시(Proxy) (0) | 2023.04.17 |
|---|---|
| 상속관계 매핑과 @MappedSuperclass (0) | 2023.04.13 |
| JPA - 엔티티와 테이블 매핑시 주의 사항 (2) | 2022.11.29 |
| JPA - 다양한 연관관계 매핑 (0) | 2022.11.28 |
| JPA - 연관관계 매핑시 고려사항 3가지 (0) | 2022.11.28 |