💡 공부하며 작성한 내용으로 잘못된 내용이 있을 수 있습니다.
🟥 Redis란?
Redis는 "REmote DIctionary Server"의 약자로, 메모리 기반의 고성능 키-값(key-value) 데이터 저장소입니다. NoSQL 계열의 데이터베이스 중 하나로 분류되며, 빠른 읽기/쓰기 성능을 위해 데이터를 디스크가 아닌 메모리에 저장합니다.
🟥 개발 배경


Salvatore Sanfilippo는 LLOOGG라는 실시간 로그 분석 툴을 개발 및 운영하던 중, 기존 MySQL의 확장성에 한계를 느끼고 이를 해결하기 위해 2009년에 Redis를 개발하였습니다. 이후 Redis는 빠르게 성장하며 전 세계적으로 널리 사용되었고, 2015년부터는 Redis Labs(현 Redis Inc.)가 프로젝트의 공식 후원 및 관리를 맡게 되었습니다.
🟥 Redis의 위상
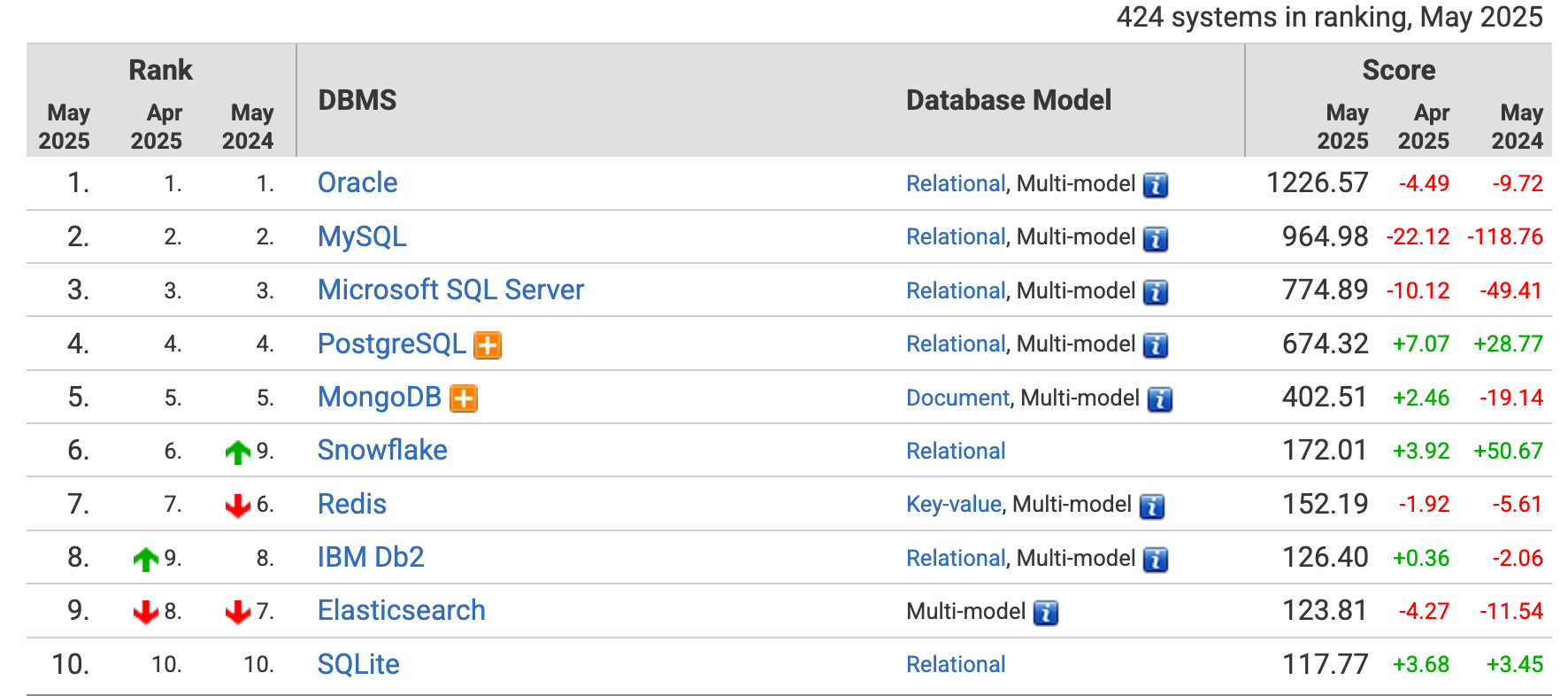
- Redis는 2009년 등장 이래 2025년 5월 현재 인메모리 기반의 Key-value 데이터베이스 중 압도적인 1위의 사용량을 자랑합니다.
- 뿐만 아니라 전체 데이터베이스 순위에서도 10위권 안에 드는 세계적으로 인기 있는 데이터베이스입니다.
🟥 라이선스 이슈와 Valkey의 등장
Redis는 원래 BSD 3-Clause 라이선스를 사용하고 있었습니다. BSD 라이선스는 저작권자 표기 규정만 준수하면 개인적이든, 상업적이든 마음대로 바꾸고 배포할 수 있는 자유로운 오픈소스 라이선스입니다. 이에 기업들도 Redis를 상업적으로 아무런 제약 없이 사용할 수 있었죠. 많은 클라우드 서비스 업체들이 Redis를 가져다 자신들의 제품에 포함시킬 수 있었던 이유도 여기에 있습니다.
하지만 2024년 3월 20일, Redis의 라이선스는 SSPL (Server Side Public License)로 변경되었습니다. 이 변화는 꽤나 파장을 일으켰습니다. SSPL은 오픈소스처럼 보이지만 제약이 존재합니다. 단순히 Redis를 설치해서 쓰는 건 상관없지만, Redis를 기반으로 한 서비스를 만들어 다른 고객에게 제공하려면, 해당 기업은 Redis뿐 아니라 그 서비스 운영 전체 구조까지 공개해야 하는 의무를 지는 조건입니다. 이런 제약 조건은 AWS, Google Cloud 같은 클라우드 기업에게는 리스크일 수밖에 없습니다. Redis에서는 "우리가 Redis를 오픈소스로 만들어도, 대형 클라우드 업체들이 그 위에서 돈만 벌고 있다"라며 라이센스 변경 이유를 밝혔습니다.
🌀 Valkey의 등장
Redis의 라이선스 변경에 반발한 오픈소스 커뮤니티는 Redis의 마지막 오픈소스 버전을 기반으로 다양한 포크 프로젝트를 출범시켰습니다. 그중 대표적인 예로는 Valkey와 Redict가 있으며, 이 중 특히 주목받고 있는 프로젝트는 Valkey입니다. Valkey는 여전히 자유로운 라이선스를 유지하면서 Redis와의 호환성을 지향하고 있으며, AWS, Google Cloud, Oracle 등 주요 클라우드 기업들이 공식적으로 참여하면서 활발히 개발이 진행되고 있습니다.
💡 Redis의 특징
- 메모리 기반으로 속도가 매우 빠릅니다.(이는 Redis를 쓰는 가장 큰 이유입니다.)


| 단위 | 의미 | 시간 |
| ns (나노초) | 10억분의 1초 | 1 ns = 0.000000001 s |
| μs (마이크로초) | 백만분의 1초 | 1 μs = 0.000001 s |
| ms (밀리초) | 천분의 1초 | 1 ms = 0.001 s |
| s (초) | 기본 단위 | 1 s |
- 기본적으로 컴퓨터의 주요 메모리는 CPU에 가까울수록 빠르면서 비싸고, 멀수록 느리면서 쌉니다.
- 관계형 데이터베이스의 경우 보조기억장치인 SSD나 HDD에 데이터가 저장되기 때문에 인메모리 데이터베이스에 비해 느린 편입니다.
- Rocks DB의 경우 디스크 기반의 Key-Value 데이터베이스로 메모리 캐시를 활용하여 읽기 성능이 좋은 편입니다. 하지만 저장은 디스크에 이루어지므로, RAM에 직접 접근하는 방식보다는 느립니다.
- 반면 Redis의 경우 인메모리 기반의 Key-Value 저장소이기 때문에 약 100ns에 불과합니다. 이는 평균 100μs의 속도를 가진 SSD에 비해 약 1000배 빠른 속도입니다.
⚡️ Cache
- Redis는 디스크 기반의 일반적인 관계형 데이터베이스(RDBMS) 보다 훨씬 빠른 메모리 기반 저장소입니다.
- 이 특성 덕분에 자주 사용되는 데이터를 Redis에 1차적으로 저장해 두고, 필요할 때 빠르게 꺼내 쓰는 캐시(Cache) 용도로 많이 활용됩니다.
- Redis는 문자열, 리스트, 해시, 집합, 정렬된 집합 등 다양한 데이터 타입을 지원하기 때문에 단순한 키-값 캐시 그 이상으로 복잡한 구조의 데이터도 효율적으로 캐싱할 수 있습니다.
🕵🏻♂️ 캐싱 전략
- 각 전략은 성능, 일관성, 데이터 특성, 시스템 구조에 따라 쓰임새가 다릅니다.
- 상황에 따라 어떤 전략이 최적인지 다르기 때문에 적절성을 고려해야 합니다.
🔸 Look-aside Cache (Lazy-loading Cache)
- 애플리케이션이 먼저 Redis 캐시에 접근하고, 캐시에 값이 없을 경우 비즈니스 로직이 데이터베이스에서 값을 조회한 뒤 캐시에 값을 저장하는 방식입니다.
- 읽기 빈도가 높고, 데이터 변경은 적은 경우에 적합합니다.(ex. 유저 프로필, 게시글 등)
- 대부분의 서비스의 기본 캐시 전략으로 사용합니다.
- 많이 쓰이긴 하지만 캐시 갱신/삭제를 개발자가 직접 관리해야 하므로 주의가 필요합니다.
흐름
- 애플리케이션 → Redis 조회
- 값없음 → DB 조회
- DB에서 가져온 값 → Redis에 저장
- 클라이언트에 응답 반환
장점
- 불필요한 데이터가 캐시에 쌓이지 않습니다.
- 캐시 미스 처리 로직이 명확합니다.
단점
- 데이터 일관성 관리를 애플리케이션 단에서 직접 해야 합니다.
🔸 Write-through Cache
- 애플리케이션이 데이터를 저장할 때 데이터베이스와 캐시에 동시에 저장하는 방식입니다.
- 데이터베이스와 캐시가 항상 동기화되어있습니다.
- 읽기는 빠르지만 쓰기 동작에 부담이 있습니다.
- 일관성이 중요한 환경에서 주로 사용됩니다.
흐름
- 애플리케이션 -> Redis, 데이터베이스에 동시 저장
장점
- 캐시와 데이터베이스 간의 일관성을 높일 수 있습니다.
- 캐시에 항상 최신 데이터가 존재합니다.
단점
- 쓰기 성능이 데이터베이스 속도에 영향을 많이 받습니다.
- 모든 데이터가 캐싱되므로 메모리 낭비가 될 수 있습니다.
🔸 Write-back / Write-behind Cache
- 데이터를 먼저 Redis에 저장하고 일정 시간 뒤 또는 조건이 충족되었을 때 백그라운드로 데이터베이스에 반영하는 방식입니다.
- 쓰기 성능이 최우선이고, 일관성의 지연 허용이 가능할 때 사용합니다.
- 사용 빈도는 낮지만 로그 수집이나 클릭 수 집계 등 특수한 상황에 매우 효과적입니다.
흐름
1. 애플리케이션 -> Redis 저장
2. 백그라운드 스레드 -> 주기적으로 데이터베이스에 저장
장점
- 데이터베이스에 바로 쓰지 않고 모아서 하기 때문에 쓰기 연산이 빠릅니다.
- 버퍼링(모아서 한 번에 쓰기)을 통해 데이터베이스에 부하를 줄일 수 있습니다.
단점
- 장애 발생 시 데이터 손실이 발생할 위험이 있습니다.
- 일관성 보장을 위한 구현이 복잡할 수 있습니다.
🔸 Read-through Cache
- 캐시에 값이 없을 경우에 캐시 시스템에서 데이터베이스를 조회하고 결과를 캐시에 저장하는 방식입니다.
- 그러나, Redis는 데이터베이스 조회를 지원하지 않으므로 캐시 라이브러리를 사용하거나, 애플리케이션 단에 로직을 직접 구현해야합니다.
흐름
- 애플리케이션 -> Redis 조회
- 캐시에 없으면 -> 캐시 라이브러리 사용 로직 or 애플리케이션이 데이터베이스를 직접 조회 로직 사용(Redis는 데이터베이스 조회를 지원하지 않음)
- 애플리케이션 -> Redis에 저장
장점
- 캐시 미스 처리 로직이 중앙화되어 있어서, 애플리케이션의 코드가 깔끔해지고 재사용성이 높습니다.
- 자주 조회되는 데이터를 자동으로 캐시에 저장하므로 성능 개선에 효과적입니다.
단점
- 구현이 복잡하거나 외부 라이브러리가 필요할 수 있습니다.
🔸 Refresh-ahead Cache
- Redis는 저장 데이터에 만료 시간(Time To Live)을 설정할 수 있습니다.
- 캐시가 만료되기 전에 미리 백그라운드에서 새 데이터를 로딩하여 갱신하는 방식입니다.
- 캐시 미스 없이 항상 데이터를 제공할 수 있습니다.
- 항상 빠른 응답이 중요한 경우 사용합니다.(실시간 대시보드 등)
흐름
- 만료 시간이 끝나기 전에 -> 백그라운드 스레드가 새 데이터로 갱신
- 사용자는 항상 유효한 데이터를 받음
장점
- 캐시 미스를 줄여 일관된 성능을 제공합니다.
- 사용자 요청 시 지연이 없습니다.
단점
- 불필요한 데이터 로딩 발생이 가능합니다.
- 스케줄링 및 백그라운드 로직이 필요하여 구현이 복잡할 수 있습니다.
🔸 TTL(Time To Live) + Eviction Policy
- Redis 키에 만료시간을 설정하고 메모리 부족 시 LRU, LFU, TTL 기반 정책으로 데이터를 자동 삭제하는 방식입니다.
- Redis에서 기본적으로 제공하는 방식입니다.
- 모든 전략과 조합이 가능합니다.
흐름
- 데이터를 캐시에 저장하며 TTL 설정을 함
- TTL이 만료되면 자동 삭제
- 메모리 초과시 기타 정책(LRU 등)에 따라 삭제
장점
- 메모리를 효율적으로 사용합니다.
- 오래되거나, 사용 안 한 데이터는 TTL 정책에 의해 자동으로 정리됩니다.
단점
- 필요한 데이터가 예기치 않게 삭제될 수 있습니다.
- 일관성 보장이 어렵습니다.
👨🏻🔬 고급 캐시 전략
🔸 Distributed Cache (분산 캐시)
- 단일 Redis 노드로 처리하기 어려운 대용량 트래픽이나 대규모 데이터를 감당하기 위해 여러 Redis 노드를 묶어 사용하는 구조입니다.
- 여러 노드를 사용함으로써 부하가 분산되어 처리 성능이 향상됩니다.
- 서비스가 커져도 수평 확장(Scale-out)하기 쉬워 유연한 구조를 만들 수 있습니다.
- Redis Cluster, Redis Sentinel은 마스터 노드 장애 시 자동으로 슬레이브 노드를 마스터로 승격시켜 무중단 서비스 제공이 가능합니다.
🔹 Redis Cluster
- Redis에서 공식적으로 제공하는 수평 확장(샤딩, Sharding) 기능입니다.
- 데이터는 자동으로 여러 노드에 나눠 저장되는데, 각 노드는 특정 범위의 키 슬롯(0~ 16,383)을 담당합니다.
- 여기서 키 슬롯은 어느 노드에 데이터를 저장할지를 결정하는 범위 단위입니다.
- Redis Cluster는 전체 키 공간을 16,384개의 슬롯(0 ~ 16383)으로 나누고, 이 슬롯 번호를 기준으로 각 노드가 담당할 슬롯의 범위를 정합니다.
- 이때 특정 키(저장할 데이터의 식별자)가 들어오면 이를 해시한 값(슬롯 번호)을 통해 어느 노드에 저장될지 결정합니다.
🔹 Redis Sentinel + Sharding(샤딩)
- Redis Sentinel은 Redis 고가용성을 위한 도구(공식 컴포넌트)로, 장애 감지 및 자동 장애 조치를 제공합니다.
- 이 구조에서는 샤딩 로직을 애플리케이션에서 직접 구현해하며, Sentinel은 각 샤드에 대한 가용성을 관리해줍니다.
- 즉, 다음과 같이 역할이 나뉩니다:
- 애플리케이션: 어떤 키를 어떤 샤드에 보낼지를 결정하는 샤딩 로직을 구현
- Sentinel: 각 샤드의 마스터 Redis가 장애 날 경우 자동으로 슬레이브를 마스터로 승격
🔸 Redis with Range(범위 기반 캐싱)
- 일정한 범위의 데이터를 캐시에 저장하거나 조회하는 방식입니다.
- 정렬된 집합(ZSET)과 리스트(List) 자료구조를 사용하면 일부 구간만 잘라서 효율적으로 데이터를 가져올 수 있습니다.
- 예를 들어 최신 게시글 10개 가져오기(0~9번 데이터 가져오기), 상위 랭킹 or 점수 조회 등이 가능합니다.
- 원하는 범위만 가져오므로 속도와 효율이 좋습니다.
🔸 Redis with Pre-sharding(사전 샤딩)
- 서버나 Redis Cluster 없이 애플리케이션에서 키를 기준으로 데이터를 미리 나누어 저장하는 방식입니다.
- 예를 들어 키 앞에 번호나 접두어를 붙여 수동으로 분산 저장할 수 있습니다.
장점
- 구현이 간단하고 속도 병목을 줄일 수 있습니다.
단점
- 샤딩 로직을 코드에서 직접 관리해야합니다.
- 노드를 추가/제거하면 키를 다시 분배해야 합니다.
🥷🏻 Redis의 주요 활용 분야
🔸 Session Store
- 사용자의 로그인 정보나 상태를 메모리에 저장해 빠르게 조회할 수 있도록 하는 방식입니다.
- Redis는 속도가 빠르고 TTL 설정이 가능해서 세션 만료 처리도 용이합니다.
- 세션 저장 외에도 JWT 리프래시 토큰 저장, 블랙리스트 관리 등에도 사용됩니다.
🔸 분산 락 (Distributed Lock)
- 여러 서버(프로세스)가 동시에 같은 자원에 접근하지 않도록 제어하는 방법입니다.
- Redis의 SET key value NX PX 명령어로 락을 설정하고, 일정 시간 후 자동 해제되도록 할 수 있습니다.
🔸 Rate Limiter
- Redis는 TTL과 원자 연산이 가능해 카운팅 및 시간제한을 활용할 수 있는 기능입니다.
- 카운팅을 활용한 다양한 곳에서 횟수를 제한할 수 있습니다.
- 로그인 시도 제한, 댓글 작성 속도 제한, API 요청 제한 등
🔸 리더보드(Leaderboard) / 랭킹 시스템
- 점수 기반으로 유저를 정렬하고 순위를 매기는 기능입니다.
- Redis의 정렬된 집합(ZSET) 자료구조를 이용하면 점수로 정렬된 리스트를 빠르게 관리할 수 있습니다.
참고
2025 오픈소스 컨트리뷰션 아카데미 Git & Redis 수업 자료
chatGPT
'넓고 얕은 데이터베이스 지식 > NoSQL' 카테고리의 다른 글
| Redis의 RESP에 대해 간단히 알아보자 (0) | 2025.05.21 |
|---|---|
| Valkey 오픈 소스를 직접 빌드하고 나만의 명령어를 추가해보자 (0) | 2025.05.13 |
| Redis & Valkey에 대해 알아보자 - 원자성과 자료구조(Siphash, Skiplist) (2) | 2025.05.11 |
| 속성으로 익히는 mongoDB (관련 용어 & 명령어 요약 정리) (0) | 2023.08.11 |
| macOS에서 mongoDB를 설치해보자 (0) | 2023.08.10 |
